|
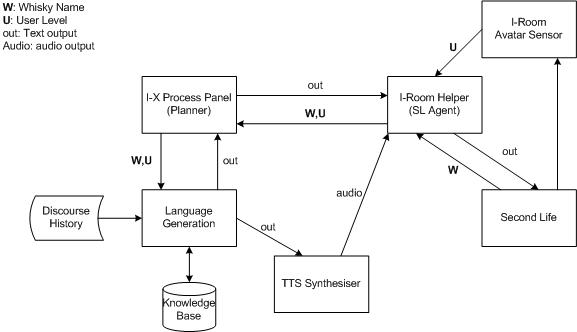
an issue-handling style of architecture, with reasoning and functional capabilities provided as plug-ins. Also via plug-ins it allows for sophisticated constraint management, and a wide range of communications and visualisation capabilities.In this implementation we will use the I-X Planner as an organiser for the activities of input/output handling and language generation process.
an "intelligent room" or "knowledgeable room" to act as a knowledge aid to support collaborative teleconferences and meetingsOne of I-Room's main components is the I-Room Helper. The Helper acts as an agent between Second Life and the real world that passes the requests of the avatars to the process panel (and in turn to the I-X Planner) and delivers messages from the external system to the room (e.g. turning on screens to show a video or writing a chat message to the avatars in the room). In this project the I-Room Helper will be used to provide the external system with the whisky name string and to deliver the NLG output in the form of written tasting notes and audio.
Colour: Rich deep gold.At the opposite end, there are very rich manually crafted tasting notes that contain information that only a human whisky expert can have. A very good example for this type of tasting notes is the Scotch Malt Whisky Society's website. A sample text about one whisky is the following:
Nose: Very powerful, "medicine", smoke, seaweed and ozone characters overlaying a sweetness.
Body: Full and strong.
Taste: A massive peated burst of flavour with hints of sweetness at the end.
Finish: Long and savoury.
One of only three operating lowland distilleries, this one distills its spirit three times and has a three wood (expression of the malt, not the golf club...) This example is from a barrel and has picked up a good orangey gold colour for its age. The first impression on the nose is sweet, as one would expect. It becomes more and more hay-like with time, and we were reminded of lying in dry, hot, hay. The taste is minty and very clean, like breathing in sharply after crunching a mint. With water a little soap reveals itself to the nose, and a slight aniseedy, peppery sensation tingles the palate. Simple and sweet, this is a lowland that does exactly as it should.Our NLG system aims at creating tasting notes that lay between these two extremes using all the information available from the knowledge base. The output text will contain sentences in the style of the emphasised parts of the above text. For this we will use a minimal amount of reasoning over the knowledge base data and for the more "iconic" phrases (e.g. like breathing in sharply after crunching a mint) we will use template expressions.
|
|
| (1) | [the nose is X] and [the palate is Y] |
| (2) | [bottled in X this whisky] [has a Y colour] |
//compare, hasRefExp, followsRefExp, "surface form"
false, false, false, "the first impression is {values}"
false, false, false, "the palate: {values}"
false, false, true, " has a {values} taste"
false, true, false, "{refExp} has a {values} taste"
false, true, false, "{values} in taste {refExp}"
true, false, false, "the palate: {compareVal}"
//numOfValues, values, "surface form"
2, salty,oily, "briny and sligtly oily -like salt
and vinegar crisps in a boat's engine room"
1, smoky, "{restValues} with a subtle smokiness"
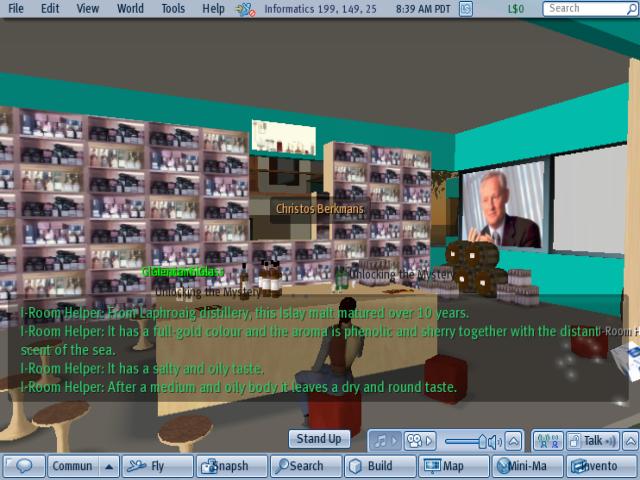 |
From Laphroaig distillery, this Islay malt matured over 10 years.
It has a full-gold colour and the aroma is phenolic and sherry together with the distant scent of the sea.
It has a salty and oily taste.
After a medium and oily body it leaves a dry and round taste.
Bottled in 1971, Millburn comes from Millburn distillery.
The colour is red and the nose: sherry like the Laphroaig, but
also dry, rich and aromatic.
The taste is sherry and malty with a subtle smokiness.
The body: smooth, firm and full and with a warm, long and
smoky finish.
Distilled in Laphroaig distillery, this Islay whisky matured
over 10 years.
Hold up your glass and see its full-gold colour.
Swirling the whisky around the glass will give the feel of the
medium and oily body.
Hold you mouth open slightly to take in the phenolic, salty and
sherry aroma.
Have a small sip and taste the oily and salty palate.
Enjoy the round and dry finish.
From Millburn distillery, this dram was bottled in 1971.
Hold up your glass and see its red colour.
Swirling the whisky around the glass will give the feel of the
smooth, firm and full body.
Add a splash of water to unleash the dry, rich, sherry and
aromatic nose.
Have a taste of the whisky, let the fire burn off and leave you
with the smoky, sherry and malty taste.
Feel the warm, long and smoky finish.
 Year of bottling
Year of bottling